SVO 论文与代码分析总结
Last updated on March 2, 2026 pm
[TOC]
概述
SVO: Semi-direct Monocular Visual Odometry
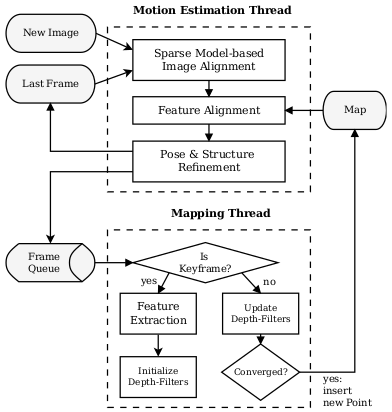
- 论文: SVO: Fast Semi-Direct Monocular Visual Odometry
- 代码(注释版):cggos/svo_cg
SVO结合了直接法和特征点法,称为 半直接单目视觉里程计。
初始化
获取第一关键帧和第二关键帧的相对位姿,并建立初始地图,代码主要在 initialization.cpp 中。
(1)处理第一帧 FrameHandlerMono::processFirstFrame
- 第一帧位姿为单位阵
new_frame_->T_f_w_ = SE3(Matrix3d::Identity(), Vector3d::Zero()) addFirstFramedetectFeatures: 获取 Shi-Tomas得分较高 且 均匀分布 的 FAST角点,并创建Features- 初始化
px_vec(Coordinates in pixels on pyramid level 0) 和f_vec(Unit-bearing vector of the feature)
- 将当前帧设置为关键帧,并检测5个对应的关键点
- 添加关键帧到地图
map_.addKeyframe(new_frame_);
(2)处理第二帧 FrameHandlerMono::processSecondFrame
addSecondFrame- 光流跟踪
trackKlt - 计算 单应性矩阵(假设局部平面场景),估计相对位姿
T_cur_from_ref_ - 创建初始地图
- 光流跟踪
- BA优化
ba::twoViewBA - 添加关键帧到地图
map_.addKeyframe(new_frame_); - 添加关键帧到深度滤波器
depth_filter_->addKeyframe
位姿估计
代码主框架在 FrameHandlerMono::processFrame()。
稀疏图像对齐(直接法)
代码主要在 SparseImgAlign。
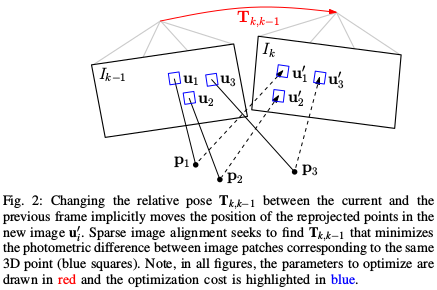
使用 稀疏直接法 计算两帧之间的初始相机位姿 T_cur_from_ref:根据 last_frame_ 的特征点 和 last_frame_ 与 new_frame_ 的相对位姿,建立损失函数(两帧之间稀疏的4x4的patch的光度误差)SparseImgAlign::computeResiduals,使用G-N优化算法获得两帧之间的位姿变换,没有特征匹配过程,效率较高。
\[ T_{k,k-1} = \arg \min_{T_{k,k-1}} \frac{1}{2} \sum_{i} \| \delta I(T_{k,k-1}, u_i) \|^2 \]
其中,
\[ \delta I(T, u) = I_k(\pi(T \cdot {\pi}^{-1} (u,d_u))) - I_{k-1}(u) \]
patch选取了4x4的大小,忽略patch的变形,并且没有做仿射变换(affine warp),加快了计算速度
在几个图像金字塔层之间迭代优化,从金字塔的最顶层(默认是第五层
klt_max_level)逐层计算(默认计算到第3层klt_min_level)广泛使用指针,比直接取值速度更快
逆向组合(inverse compositional) 算法,预先计算雅克比矩阵
precomputeReferencePatches,节省计算量几处双线性插值方法对提高精度有帮助
最后,cur_frame_->T_f_w_ = T_cur_from_ref * ref_frame_->T_f_w_;
特征对齐(光流法)
代码入口在 Reprojector::reprojectMap。
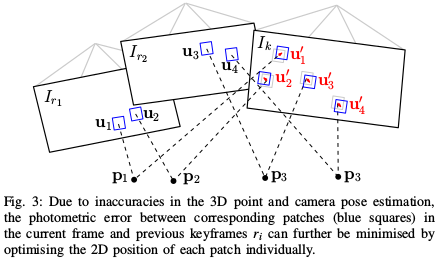
通过上一步的帧间匹配能够得到当前帧相机的位姿,但是这种 frame-to-frame 估计位姿的方式不可避免的会带来累计误差从而导致漂移。
稀疏图像对齐之后使用 特征对齐,即通过地图向当前帧投影,并使用 逆向组合光流 以稀疏图像对齐的结果为初始值,完成基于patch的特征匹配,得到更精确的特征位置。
基于 光度不变性假设,特征块在以前参考帧中的亮度应该和new frame中的亮度差不多,所以重新构造一个残差,对特征预测位置进行优化(代码主要在 Matcher::findMatchDirect):
\[ u_i' = \arg \min_{u_i'} \frac{1}{2} \| I_k(u_i') - A_i \cdot I_r(u_i) \|^2 \]
优化变量是 像素坐标位置
光度误差的前一部分是当前图像中的亮度值;后一部分不是 \(I_{k-1}\) 而是 \(I_r\),即它是根据投影的3D点追溯到其所在的KF中的像素值
选取了8x8的patch,由于是特征块对比并且3D点所在的KF可能离当前帧new frame比较远,所以光度误差还加了一个 仿射变换 \(A_i\),可以得到亚像素级别的精度
对于每个特征点单独考虑,找到和当前帧视角最接近的共视关键帧
getCloseViewObs(这个关键帧和当前帧的视角差别越小,patch的形变越小,越可以更精准地匹配)
该过程通过 inverse compositional Lucas-Kanade algorithm 求解,得到优化后更加准确的特征点预测位置。
位姿和结构优化(特征点法)
代码主要在 pose_optimizer::optimizeGaussNewton 和 FrameHandlerBase::optimizeStructure
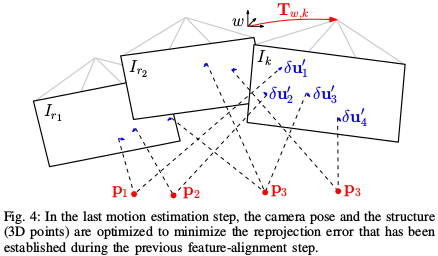
motion-only BA
\[ T_{k,w} = \arg \min_{T_{k,w}} \frac{1}{2} \sum_{i} \| u_i - \pi(T_{k,w} \cdot p_i) \|^2 \]
- 优化变量是 相机位姿
structure-only BA
- 优化变量是 三维点坐标
local BA
- 附近关键帧和可见的地图点都被优化了,这一小步在fast模式下是不做的
重定位
代码主要在 FrameHandlerMono::relocalizeFrame。
重定位效果一般,有待改进。
建图(深度滤波器)
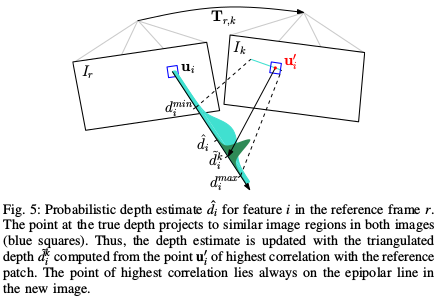
SVO把像素的深度误差模型看做概率分布,使用 高斯--均匀混合分布的逆深度(深度值服从高斯分布,局外点的概率服从Beta分布),称为 深度滤波器(Depth Filter),每个特征点作为 种子Seed(深度未收敛的像素点)有一个单独的深度滤波器。
- 初始化种子:如果进来一个 关键帧,就提取关键帧上的新特征点,初始化深度滤波器,作为种子点放进一个种子队列中
- 更新种子:如果进来一个 普通帧,就用普通帧的信息,更新所有种子点的概率分布;如果某个种子点的深度分布已经收敛,就把它放到地图中,供追踪线程使用
Relate
初始化种子
代码主要在 DepthFilter::initializeSeeds。
- 当前帧上已经有的特征点,占据住网格
- 多层金字塔FAST特征检测并进行非极大值抑制,映射到第0层网格,每个网格保留Shi-Tomas分数最大的点
- 对于所有的新的特征点,初始化成种子点Seed
- 高斯分布均值:
mu = 1.0/depth_mean - 高斯分布方差:
sigma2 = z_range*z_range/36,其中z_range = 1.0/depth_min
- 高斯分布均值:
更新种子(深度滤波 / 深度估计)
深度滤波 DepthFilter::updateSeeds 主要过程:
- 极线搜索与三角测量
Matcher::findEpipolarMatchDirect - 计算深度不确定度
DepthFilter::computeTau - 深度融合,更新种子
DepthFilter::updateSeed - 初始化新的地图点,移除种子点
深度估计值(极线搜索)
根据 深度均值
mu和深度方差sigma2确定深度范围 \([d_{\min},d_{\max}]\),计算极线计算仿射矩阵
warp::getWarpMatrixAffine(帧间图像发生旋转)极线上搜索匹配:通过RANSAC计算ZMSSD获取最佳匹配点坐标
- 当计算的极线长度小于两个像素时,直接采用下一步的图像对齐
- 否则,继续沿极线搜索匹配
光流法亚像素精度提取(图像对齐)
feature_alignment::align2D三角法恢复深度Z
depthFromTriangulation(Triangulate in SVO)
深度估计不确定度
REMODE 对由于特征定位不准导致的三角化深度误差进行了分析
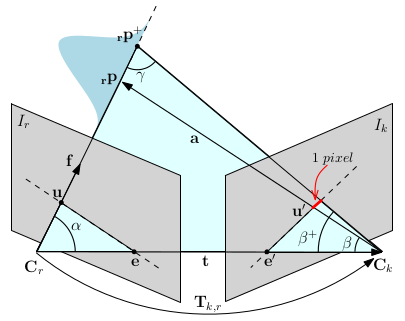
假设 焦距为 \(f\),像素扰动为 px_noise = 1.0,角度变化量 px_error_angle 为 \(\delta \beta\) 则
\[ \tan \frac{\delta \beta}{2} = \frac{1.0}{2f} \]
得
\[ \delta \beta = 2 \arctan \frac{1.0}{2f} \]
则
\[ \beta^{+} = \beta + \delta \beta \]
\[ \gamma^{+} = \pi - \alpha - \beta^{+} \]
已知 \(t\) 为 T_ref_cur.translation(),根据正弦定理
\[ Z^{+} = \|t\| \frac{\sin \beta^{+}}{\sin \gamma^{+}} \]
所以,深度不确定度 tau 为 \(\tau = Z^{+} - Z\)
逆深度不确定度(标准差) tau_inverse 为:
1 | |
即
\[ \tau_{inv} = \frac{1}{2} (\frac{1}{Z-\tau} - \frac{1}{Z+\tau}) \]
深度融合
代码主要在 void DepthFilter::updateSeed(const float x, const float tau2, Seed* seed)。
SVO的融合是不断利用最新时刻深度的观测值,来融合上一时刻深度最优值,直至深度收敛。
通过上面两步得到 逆深度测量值 \(x=\frac{1}{Z}\) 1./z 和 逆深度不确定度 \(\tau_{inv}\),则 逆深度 服从 高斯分布
\[ \mathcal{N}(x, \tau_{inv}^2) \]
SVO 采用 Vogiatzis的论文 Video-based, real-time multi-view stereo 提到的概率模型,使用 高斯--均匀混合分布的深度滤波器,根据 \(x\) 和 \(\tau_{inv}\) 更新以下四个参数:
- 逆深度高斯分布的均值 \(\mu\)
seed->mu - 逆深度高斯分布的方差 \(\sigma^2\)
seed->sigma2 - Beta分布的 \(a\)
seed->a - Beta分布的 \(b\)
seed->b
更新过程(Vogiatzis的Supplementary matterial)如下:

其中,论文公式19有误(代码正确),应为
\[ \frac{1}{s^2} = \frac{1}{\sigma^2} + \frac{1}{\tau_{inv}^2} \]
最终,得到收敛的逆深度的最佳估计值 seed->mu。
新的地图点
如果种子点的方差 seed->sigma2,小于深度范围/200的时候,就认为收敛了,它就不再是种子点,而是 TYPE_CANDIDATE 点。
TYPE_CANDIDATE 点被成功观察到1次,就变成 TYPE_UNKNOWN 点;TYPE_UNKNOWN 被成功观察到10次,就变成TYPE_GOOD 点;如果多次应该观察而没有被观察到,就变成 TYPE_DELETED 点。
总结与讨论
特征点提取在地图线程,跟踪使用光流法
后端的特征点只在关键帧上提取,用FAST加金字塔
上一个关键帧的特征点在这一个关键帧上找匹配点的方法,是用极线搜索,寻找亮度差最小的点,最后再用深度滤波器把这个地图点准确地滤出来
重定位比较简单,没有回环
深度滤波器使用的是高斯--均匀混合分布
SVO对PTAM的改进主要在两个方面:高效的特征匹配、鲁棒的深度滤波器
在Tracking线程,当前帧的特征点是从上一帧用光流法传递过来的,只有在Mapping线程
DepthFilter插入新关键帧时才需要提取特征点,不需要每一帧都提取特征点PTAM和ORB-SLAM只用两帧图像三角化出地图点,只要地图点没有被判定为外点,就固定不变了(除非BA阶段调整);而SVO的深度滤波器会根据多帧图片不断收敛地图点的不确定度,从而得到更可靠的地图点。因为地图点更可靠,所以SVO只需要维护更少的地图点(PTAM一般维护约160到220个特征点,SVO在fast模式下维护约120个地图点),从而加快了计算速度。
参考文献
- SVO: Fast Semi-Direct Monocular Visual Odometry
- ivcj2010supp, Supplementary matterial
- REMODE: Probabilistic, Monocular Dense Reconstruction in Real Time
- SVO 代码笔记
- svo: semi-direct visual odometry 论文解析
- 能否具体解释下svo的运动估计与深度估计两方面?
- SVO原理解析
- svo的Supplementary matterial 推导过程
- 深度滤波器详细解读